ジェネレーティブAIの急速な発展は、あなたを興奮させるか、少し不安にさせるかのどちらかだろう。いずれにせよ、人類はすでに後戻りできないところまで来ているのだから、無視することに意味はない。技術的な進歩はここに来ており、控えめに言っても間違いなく我々の業界に影響を与えるだろう。映像作家として、私たちは責任を持って、テクノロジーの実態がどうなっているのか、そして最も倫理的かつ持続的にテクノロジーにアプローチするにはどうすればいいのかを皆さんにお伝えする義務がある。それを念頭に置いて、我々はAIビデオジェネレーターの概要をまとめ、その現在の能力と限界を強調した。
当サイトでこのトピックを長く追っている方なら、グーグルがテキスト説明文から動画像を生成するベビーステップを踏み出したという最初の記事を覚えているかもしれない。約1年前、同社は有望な研究論文と最初のテストの例を発表した。しかし、グーグルのモデルはまだ一般公開されていなかった。現在では、このアイデアが現実のものとなっただけでなく、実用的なAI動画生成ツールが数多く登場している。
まあ、”動く “という表現は強すぎるかもしれない。では、それらを試してみて、いつ、どのように使うのが良いのかについて話そう。
AIビデオジェネレーター:マーケットリーダー
テキスト・コマンドに基づいてビデオを生成し、デジタルでスタイライズできるインテリジェントなAIモデルを最初に展開したのはランウェイだ。2023年春以来、彼らはクリップを強化するためのツール(AIアップスケール、人工スローモーション、ワンクリックでの背景除去など)を次々と発表し、独立系クリエイターのために多くのVFXプロセスをシンプルにした。しかし、ここでは同社の主力製品であるディープラーニング・ネットワーク「Gen-2」のみをレビューする。
Runwayは今でも動画生成の分野でトップに君臨しているが、現在では競合他社もいくつか存在する。最も有名なのはPikaだ。
PikaはAIを活用したアイデアから動画へのプラットフォームです。技術的なことはたくさんありますが、基本的には、入力さえできれば、Pikaはそれを動画にすることができます。
ウェブサイトからの説明
Pikaのクリエイターが強調しているように、彼らの技術チームは独自のビデオモデルをゼロから開発し、トレーニングした。しかし、どのようなデータでトレーニングされたかは公表していない(この質問については後述する)。最近まで、PikaはベータテストとしてDiscordサーバーを通じてのみ動作し、完全に無料だった。今でもこの方法で試すことができるし(上のDiscordのリンクをクリックすればいい)、ウェブ・インターフェイスで、アップグレードされたばかりのモデルPika 1.0に向かうこともできる。
両社とも、製品の基本プランを無料で提供している。Runwayは、限られた世代にのみプラットフォームのテストを許可している。Pikaの場合、30クレジット(短編ビデオ3本分)を入手でき、毎日補充される。また、生成されるクリップには基本的な長さ(RunwayのGen-2は4秒、PikaのAIは3秒)があり、数回延長することができる。デフォルトの解像度は768×448(Gen-2)から1280×720(Pika)まで異なる。ただし、各ソフトウェアで直接アップスケールすることもできるし(有料プランもある)、TopazLabsのような外部のAIツールを使うこともできる。
オープンソースプロジェクトはどうだろうか?
この秋、画像生成の分野でもうひとつのビッグネームが動画分野に参入した。Stability AIは、Stable Video Diffusion(SVD)-静止画から動画を生成できる初のモデル-を発表した。彼らの他のプロジェクトと同様、オープンソースであるため、GitHubでコードをダウンロードし、ローカルでモデルを実行することができる。その技術的な能力については、公式の研究論文を読んでほしい。AIコードと格闘することなくSVDを見てみたい方は、彼らのHuggingFaceスペースで無料のオンライン・コミュニティ・デモンストレーションが見られる。
今のところ、SVDは14フレームと25フレーム、毎秒3〜30フレームの間でカスタマイズ可能なフレームレートで動画を生成できる2つの画像から動画へのモデルで構成されている。クリエイターが主張するように、外部のユーザー嗜好調査では、Stable Video Diffusionが競合他社のモデルを凌駕することが示された:
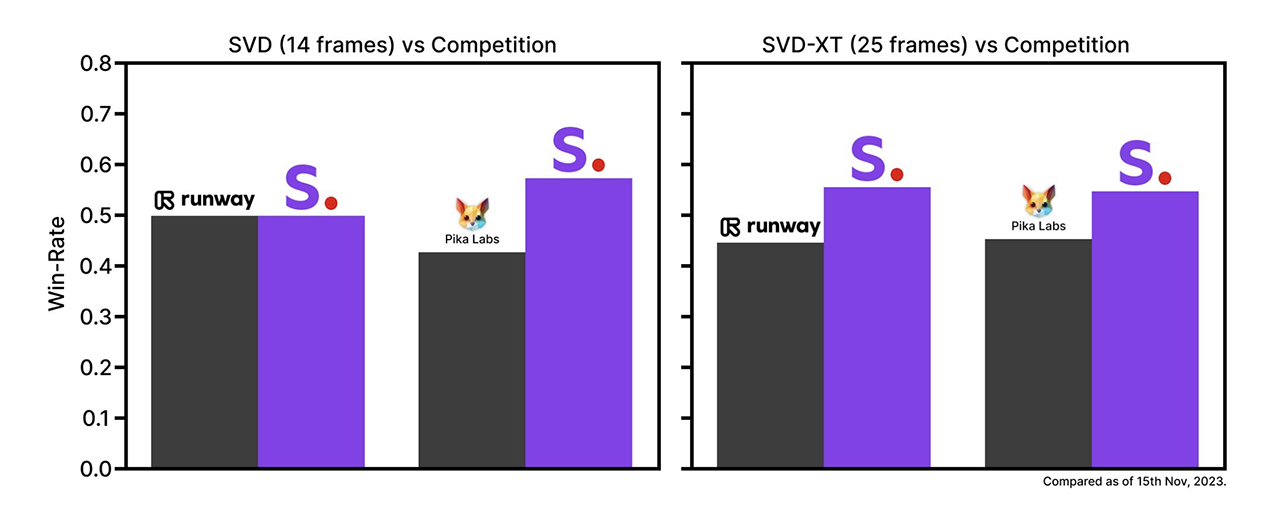
さて、その評価がテストに耐えられるかどうか見てみよう。現時点では、他の画像から動画への生成ツールと比較することしかできない。Stability AIはまた、テキストから動画へのモデルも近々展開する予定だ。
テキストから動画を生成 – 並べて比較する
それでは実験を始めよう。これが私のテキスト・プロンプトだ: 「ある女性が窓際に立ち、外に降り積もる夕方の雪を見ている。最初の結果は、Pikaの無料ベータモデルによるもので、Discordチャンネルで直接作成された:
初期の研究発表としては悪くないだろう?女性はリアルとは言い難く、なぜか雪があちこちに降っているが、全体的な雰囲気と外の明かりは気に入っている。新しいPikaと比べてみよう。同じ文章説明で動画の結果が違う:
さて、ここで何が起こったのか?この不気味な整形顔の女性は、正直言って私を恐怖に陥れる。また、最初の窓はどこに行ったのだろう?今、彼女はただ雪の中で外に立っているだけで、それは間違いなく私が求めた世代ではない。すでに時代遅れのモデルのものだが、なんとなく前の結果の方が好きだ。後でもう一度チャンスを与えよう:
Gen-2もまた、降りしきる雪を窓の外だけにとどめることはできなかったが、このアウトプットがどれほど映画的かわかるだろう。画像全体のクオリティ、女性の髪に当たる光、被写界深度、フォーカス……もちろん、このクリップは完璧とは言い難く、AIによって生成されたものだとすぐにわかるだろう。しかし、その差は大きく、モデルは確実に学習し続けるだろう。
AIモデルの学習速度は速いが、苦戦もしている
いくつかのテストを行った結果、ビデオジェネレーターはかなり苦労していることがわかった。特に、フレーム内で生き生きとした動きを得たい場合、多くの場合、彼らはずさんな結果を出す。前回の比較では、RunwayのAIはより高品質な映像を生成することがわかった。何度やっても、走るキツネの動画は撮れなかったからだ:
驚いたことに、Pikaの新しいAIモデルはもっとまともな結果を出してくれた。確かにフレーミングはひどいし、キツネは安っぽいアニメから飛び出してきたみたいだが、少なくとも足は動いている!
ところで、これはAIモデルの学習の速さを示す良い例だ。上の動画(Pika 1.0による)と、私が以前のPikaモデル(Discord内)の助けを借りて作成した下の動画を比べてみてほしい。テキスト入力は同じだが、生成されたコンテンツの違いは劇的だ:
AIビデオジェネレーターで画像をアニメーション化する
私が思うに、現在のビデオジェネレーターのもう少し良い応用アイデアは、風景写真や抽象的な画像を作成したり、アニメーションさせたりすることだ。例えば、これはMidjourney V6が生成した、黒い背景の上にランダムな大きさの金色の粒子(光の火花、魔法、塵など何でも構わない)の画像だ:

このレビューの前半で紹介したAIビデオジェネレーターは、いずれも静止画をアップロードしてアニメーション化することができる。追加のテキスト入力を必要とせず、勝手に進むものもある。例えば、RunwayのGen-2はこんな感じだ:
どうだろう?クレジットのテキストの背景のフィラーとしてはうまく機能するかもしれないが、動きに多様性がないのが気になる。いろいろ遊んでみた結果、「モーション・ブラシ」と呼ばれる特別な機能を使うと、もっと良い結果が得られた。このツールは、AIモデルにベータテストとして統合されたもので、静止画の特定の領域をマークし、正確な動きを定義することができる。
Pikaのブラウザ・モデルは、アップロードされた画像に追加のテキスト記述を要求したため、出力は期待通りにはならなかった:
最後の爆発はともかく、動きの芸術と手ブレが気に入らない。私のビジョンでは、金色の粒子は一貫して浮いているはずだ。もう一回、Stable Video Diffusionのコミュニティデモを試してみよう:
これはどうだろう!もちろん、この例は6fpsしかなく、AIモデルは明らかに背景からパーティクルを分離できないが、全体的な動きは私が思い描いていたものにかなり近づいている。もしかしたら、もっと試行錯誤を重ね、徹底的にトレーニングすれば、SVDは満足のいく映像結果を示してくれるかもしれない。
一貫性の問題とその他の限界
さて、これらの例を見てきた結果、AIビデオジェネレーターはまだ、撮影監督や2D/3Dアニメーターの仕事を引き継ぐまでには至っていないと言っていいだろう。フレーム間の一貫性がなく、結果には多くの奇妙なアーティファクトがあり、キャラクター(人間であれ動物であれ)の動きは少しもリアルに感じられない。
また、現時点では、一般的なプロセスでは、最初のビジョンに近いまともな生成ビデオを得るのに、あまりにも多くの労力を必要とする。カメラを持って “普通の方法 “で望むショットを撮る方が簡単なように思える。
同時に、AIが独自のアイデアを生み出したり、ストーリーに最適なフレーミングを慎重に考えたりするわけでもない。また、映像制作者以外が常に意識しながら映像を生成するわけでもない。だから、ビジュアルストーリーテリングツールを適用し、美しく進化する映画撮影を作り上げることは、私たち人間の手に委ねられると私は考えている。
その他にも、注意すべき制限がいくつかある。例えば、Stable Video Diffusionは商用目的でのモデルの使用を許可していない。無償のRunwayやPikaでも同じ問題に直面するだろう。同時に、有料サブスクリプションを取得すると、Pikaはウォーターマークを削除し、商業的権利を認める。
しかし、私は今のところ、生成された動画を広告や映画に使用することはお勧めしない。なぜなら、この生成AIの使用には大きな倫理的問題があり、まず規制と帰属の解決策が必要だからだ。どのようなデータで学習されたかは誰も知らない。おそらく、データベースはネット上で見つかるあらゆるもので構成されているため、許可を得ておらず、帰属表示も得ていないアーティストの絵や写真、その他の作品が大量に含まれている。この問題を異なる方法で処理しようとしている企業のひとつに、AIモデル「Firefly」を持つアドビがある。彼らはまた、昨年の春にビデオAIツールを発表したが、それはまだ制作中だ。
私たちはどのような形でAIを活用できるのだろうか?
AIが生成したコンテンツがストック映像に取って代わる日も近いと言う人もいる。正直なところ、私はそうは思わないが、いずれわかるだろう。私の考えでは、ジェネレーティブAIツールを使う最善の方法は、例えばプリプロダクションの段階で、ビジョンを素早く伝えることだ。インスピレーションの収集やアーティスティックなムードボードの作成にはテキストから画像へのモデルが便利だが、ビデオジェネレーターはプリビジュアライゼーションの迅速なソリューションになるだろう。もしあなたが私のように、ストーリーリールを作るのに、自分の下手な落書きを次々と使っているのなら、ビデオジェネレーターは大きなアップグレードになるだろう。上で見てきたように、完璧な結果は得られないが、ストーリーを下書きし、動画でプリビズするには十分すぎる。
もうひとつ思いつくのは、YouTubeチャンネルやプレゼンテーション用に静止画をアニメーション化することだ。最近のクリエイターは、写真をよりダイナミックに見せるために、デジタルズームインやフェイクパンを加える傾向がある。AI動画ジェネレーターの助けを借りれば、よりエキサイティングな選択肢を選ぶことができるだろう。
まとめ
テキストを画像に変換するAI「Midjourney」の開発者は、ビデオジェネレーターの開発に取り組んでおり、数カ月以内に発売する予定であることも発表した。そして、今年中にもっと多くのものが登場することは間違いないだろう。つまり、私たちは目をそらして無視することもできるし、この進歩を受け入れ、倫理的な応用を見つけるために協力することもできる。加えて、フェイクコンテンツが間もなく増加すること、そしてインターネット上で目にするものすべてを信じるべきではないことを人々に教育することも極めて重要だ。
特徴画像:ランウェイとSVDによって生成されたビデオのスクリーンショット